To Datablog της Guardian στο παρασκήνιο
Όταν παρουσιάσαμε το Datablog, δεν είχαμε ιδέα ποιος θα ενδιαφερόταν για ακατέργαστα δεδομένα, στατιστικά και οπτικοποιήσεις. Όπως αναρωτήθηκε ένας αρκετά ανώτερος στο γραφείο μου «Γιατί κανείς να ήθελε κάτι τέτοιο;».
Το Datablog της Guardian, το οποίο επιμελήθηκα, επρόκειτο να είναι ένα μικρό blog που θα προσφέρει ολοκληρωμένα τα δεδομένα που βρίσκονται πίσω από τις ειδήσεις μας. Τώρα αποτελείται από μια αρχική σελίδα• έρευνες για στοιχεία που αφορούν την παγκόσμια διακυβέρνηση και ανάπτυξη• οπτικοποιήσεις δεδομένων από τους γραφίστες της Guardian και από το διαδίκτυο, καθώς και εργαλεία για την εξερεύνηση στοιχείων που σχετίζονται με τις δημόσιες δαπάνες. Κάθε μέρα, χρησιμοποιούμε τα φύλλα εργασίας της Google για να μοιραστούμε το σύνολο των δεδομένων που βρίσκονται πίσω από τη δουλειά μας• Οπτικοποιούμε και αναλύουμε τα δεδομένα αυτά, και στη συνέχεια τα χρησιμοποιούμε για να παρέχουμε ιστορίες για την εφημερίδα και τον δικτυακό μας τόπο.
Όντας ένας συντάκτης ειδήσεων - δημοσιογράφος που δουλεύει με τα γραφικά, αποτέλεσε μια φυσιολογική προέκταση της δουλειάς που ήδη έκανα, το να συσσωρεύω νέα σύνολα δεδομένων και να τα οργανώνω κάνοντας τα πιο αξιοποιήσιμα σε μια προσπάθεια να κάνω κατανοητές τις ειδησεογραφικές ιστορίες της ημέρας.
Η ερώτηση που μου τέθηκε έχει απαντηθεί για μας. Υπήρξαν μερικά απίστευτα χρόνια όσον αφορά τα δημόσια δεδομένα (που σχετίζονται με τη δημόσια σφαίρα). Ο πρόεδρος Ομπάμα στην πρώτη του νομοθετική πράξη, άνοιξε τους «θόλους» δεδομένων της Αμερικανικής Κυβέρνησης, και το παράδειγμα του ακολουθήθηκε σύντομα από κυβερνητικούς δικτυακούς τόπους δεδομένων ανά τον κόσμο: Στην Αυστραλία, τη Νέα Ζηλανδία αλλά και το Data.gov.uk της Βρετανικής Κυβέρνησης.
Είχαμε το σκάνδαλο με τις δαπάνες μελών του Κοινοβουλίου (MPs), η πιο απροσδόκητη περίπτωση δημοσιογραφίας δεδομένων για τους Βρετανούς – η συνέπεια που προέκυψε σήμαινε πως η Κυβέρνηση είναι τώρα υποχρεωμένη να αφήνει ελεύθερες, τεράστιες ποσότητες δεδομένων κάθε χρόνο.
Είχαμε τις γενικές εκλογές όπου κάθε ένα από τα κύρια πολιτικά κόμματα ήταν δεσμευμένο για τη διαφάνεια των δεδομένων, ανοίγοντας τους δικούς μας «θόλους» δεδομένων στον κόσμο. Είχαμε εφημερίδες που αφιέρωναν πολύτιμο χώρο σε στήλες στην κυκλοφορία της βάσης δεδομένων COINS (Combined Online Information System – Σύστημα πληροφοριών με ανάλυση των δαπανών του κράτους) του Υπουργείου Οικονομικών.
Την ίδια ώρα, καθώς το δίκτυο αντλούσε όλο και περισσότερα δεδομένα, αναγνώστες απ’ όλο τον κόσμο ενδιαφέρονται τώρα περισσότερο από ποτέ για τα ακατέργαστα στοιχεία που βρίσκονται πίσω από τις ειδήσεις. Όταν παρουσιάσαμε το Datablog, σκεφτήκαμε πως το κοινό θα ήταν οι προγραμματιστές εφαρμογών. Στη πραγματικότητα, είναι οι άνθρωποι που θέλουν να μάθουν περισσότερα για τις εκπομπές άνθρακα, τη μετανάστευση στην Ανατολική Ευρώπη, την κατάρρευση με τους θανάτους στο Αφγανιστάν ή ακόμα και το πόσες φορές χρησιμοποίησαν τη λέξη «αγάπη» στα τραγούδια τους οι Beatles (613).
Σταδιακά, η δουλειά στο Datablog έχει εκφράσει και συμπληρώσει τις ιστορίες που αντιμετωπίσαμε. Συλλέξαμε 458,000 έγγραφα σχετικά με τις δαπάνες των μελών του Κοινοβουλίου και αναλύσαμε τα λεπτομερή δεδομένα για τα οποία τα μέλη του Κοινοβουλίου είχαν ισχυριστεί κάτι. Βοηθήσαμε τους χρήστες μας να εξερευνήσουν λεπτομερείς βάσεις δεδομένων με τις δαπάνες του Υπουργείου Οικονομικών και δημοσιεύσαμε τα δεδομένα που βρίσκονται πίσω από τις ειδήσεις.
Αλλά η αλλαγή του παιχνιδιού για τη δημοσιογραφία δεδομένων συνέβη την Άνοιξη του 2010, ξεκινώντας από ένα φύλλο εργασίας: 92,201 σειρές δεδομένων, που κάθε μία περιελάμβανε μια λεπτομερέστατη ανάλυση για ένα στρατιωτικό γεγονός στο Αφγανιστάν. Αυτά συνέστησαν και τις διαρροές εγγράφων (war logs) για τον πόλεμο στο Wikileaks. Το πρώτο μέρος, με άλλα λόγια. Επρόκειτο να υπάρχουν δύο ακόμη επεισόδια να ακολουθήσουμε: Ο πόλεμος στο Ιράκ και οι συναλλαγματικές ισοτιμίες λίρας - δολαρίου. Ο επίσημος όρος για τα δύο πρώτα μέρη ήταν SIGACTS (Significant Actions Database): Η σημαντική βάση δεδομένων των δράσεων-στρατιωτικών επιχειρήσεων του Αμερικανικού στρατού.
Στους ειδησεογραφικούς οργανισμούς όλα σχετίζονται με βάση την γεωγραφία και την εγγύτητα με το γραφείο ειδήσεων - σύνταξης (news desk). Εάν είσαι κοντά, είναι εύκολο να προτείνεις ιστορίες και να γίνεις μέρος της διαδικασίας• Αντιθέτως, έξω από το οπτικό πεδίο είναι κυριολεκτικά αδιανόητο. Πριν από το WikiLeaks, ήμασταν τοποθετημένοι σε έναν διαφορετικό όροφο, με τα γραφιστικά. Με την εμφάνιση του WikiLeaks έκτοτε, έχουμε τοποθετηθεί στον ίδιο όροφο δίπλα στην αίθουσα των ειδήσεων. Αυτό σημαίνει πως είναι ευκολότερο για μας να προτείνουμε ιδέες στο γραφείο αλλά και για τους ρεπόρτερς που βρίσκονται μέσα στην αίθουσα σύνταξης να μας σκεφτούν για να βοηθήσουμε με τις ιστορίες.
Δεν πάει πολύς καιρός από τότε που οι δημοσιογράφοι αποτελούσαν τους «φύλακες» των επίσημων δεδομένων. Εμείς θα γράφαμε ιστορίες για τα νούμερα τις οποίες κυκλοφορούσαμε σε ένα ευγνώμων κοινό, που δεν ενδιαφέρονταν για τα ακατέργαστα στατιστικά. Η ιδέα μας να επιτρέπουμε τις ακατέργαστες πληροφορίες στις εφημερίδες μας, αποτέλεσε ανάθεμα.
Η δυναμική αυτή πέρα από την αναγνώριση, έχει αλλάξει τώρα. Ο ρόλος μας είναι να γίνουμε ερμηνευτές• βοηθώντας τους ανθρώπους να κατανοήσουν τα δεδομένα έστω απλά δημοσιεύοντας τα, επειδή έτσι κι αλλιώς παρουσιάζουν ενδιαφέρον από μόνα τους.
Αλλά τα νούμερα χωρίς ανάλυση είναι απλά νούμερα, κάτι με το οποίο συμβαδίζουμε. Όταν ο Πρωθυπουργός της Βρετανίας ισχυρίστηκε πως οι εξεγέρσεις τον Αύγουστο του 2011 δεν σχετίζονταν με τη φτώχεια, ήμασταν σε θέση να απεικονίσουμε τις διευθύνεις των εξεγερμένων με βάση τους δείκτες της φτώχειας προκειμένου να δείξουμε την αλήθεια πίσω από τον ισχυρισμό.
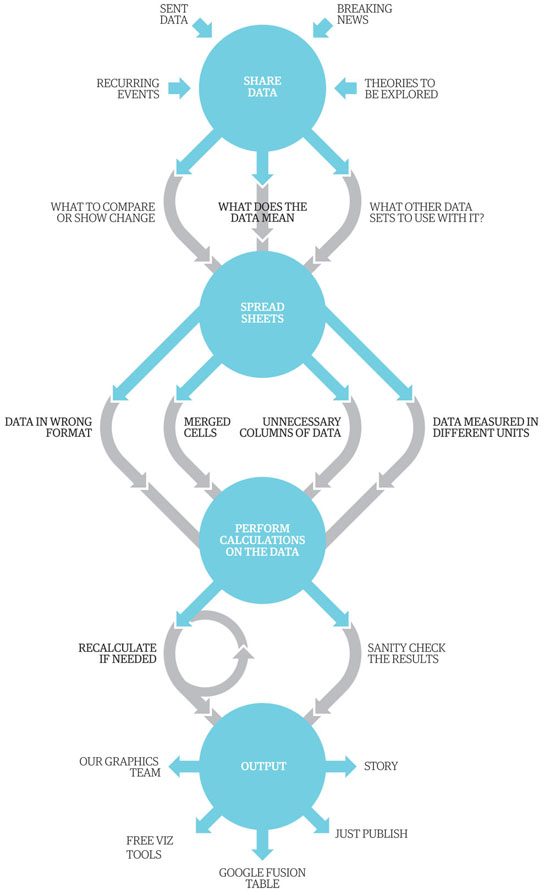
Πίσω από όλες αυτές τις ιστορίες μας που βασίζονται στη δημοσιογραφία δεδομένων, υπάρχει μια διαδικασία. Μια διαδικασία που αλλάζει συνεχώς καθώς χρησιμοποιούμε νέα εργαλεία και τεχνικές. Κάποιοι άνθρωποι ισχυρίζονται πως η απάντηση σχετίζεται με το να γίνεις ένα είδος σούπερ χάκερ, να γράφεις κώδικα και να εμβαθύνεις στην SQL. Μπορείς να αποφασίσεις να ακολουθήσεις την προσέγγιση αυτή. Αλλά μεγάλο μέρος της δουλειάς που κάνουμε, αφορά μόνο το Excel. Πρώτα απ’ όλα, εντοπίζουμε τα δεδομένα ή τα λαμβάνουμε από μια πληθώρα πηγών, όπως οι έκτακτες ειδήσεις, τα κυβερνητικά στοιχεία, οι δημοσιογραφικές έρευνες και ούτω καθεξής. Στη συνέχεια, ξεκινάμε να εξετάσουμε προσεκτικά τι μπορούμε να κάνουμε με τα δεδομένα• χρειαζόμαστε να τα συνδυάσουμε με κάποιο άλλο σύνολο δεδομένων; Πως μπορούμε να δείξουμε τις αλλαγές στην πάροδο του χρόνου; Αυτά τα λογιστικά φύλλα συχνά πρέπει να είναι σοβαρά συμμαζεμένα – όλες αυτές οι περιττές στήλες και τα περίεργα συγχωνευμένα κελιά δεν βοηθούν στην πραγματικότητα. Και αυτό, υποθέτοντας πως δεν είναι PDF, αποτελεί το χειρότερο από όλα τα γνωστά φορμάτ που υπάρχουν για δεδομένα.
Συχνά, επίσημα δεδομένα έρχονται μαζί με την προσθήκη των επίσημων κωδικών τους• κάθε σχολείο, νοσοκομείο, περιφέρεια και τοπική αρχή έχει έναν μοναδικό κωδικό αναγνώρισης.
Οι χώρες έχουν επίσης αντίστοιχους κωδικούς) (για παράδειγμα ο κωδικός του Ηνωμένου Βασιλείου είναι GB). Είναι χρήσιμοι επειδή μπορεί να θέλεις να ξεκινήσεις να επεξεργάζεσαι μαζί σύνολα δεδομένων, και είναι εκπληκτικό το πόσες διαφορετικές ορθογραφίες και συνθέσεις λέξεων μπορείς να βρεις με αυτόν τον τρόπο. Υπάρχει η Βιρμανία και η Μιανμάρ για παράδειγμα που είναι το ίδιο, ή η Fayette County στις Ηνωμένες Πολιτείες (υπάρχουν 11 σαν κι αυτήν στις πολιτείες από την Τζώρτζια μέχρι την Γουέστ Βιρτζίνια). Οι κωδικοί μας επιτρέπουν να συγκρίνουμε όλες αυτές τις κοινές λέξεις.
Και το τέλος αυτής της ιστορίας είναι η παραγωγή: θα είναι μια ιστορία, ένα γραφικό ή μια οπτικοποίηση, αλλά και τι εργαλεία θα χρησιμοποιήσουμε; Τα καλύτερα εργαλεία για μας είναι τα δωρεάν με τα οποία μπορούμε να παράγουμε κάτι στα γρήγορα. Τα πιο πολύπλοκα γραφήματα παράγονται από την ομάδα των προγραμματιστών μας.
Αυτό σημαίνει πως συνήθως χρησιμοποιούμε τα σχέδια της Google για μικρά γραμμικά γραφήματα και πίτες, ή τους πίνακες σύντηξης (Fusion Tables) της Google για την εύκολη και γρήγορη δημιουργία χαρτών.
Μπορεί να φαίνεται καινούργιο, αλλά δεν είναι.
Στο πρώτο τεύχος της Guardian που κυκλοφόρησε στο Μάντσεστερ (Σάββατο 5 Μαΐου, 1821), τα νέα βρισκόταν στην πίσω σελίδα όπως σε όλα έντυπα της συγκεκριμένης ημέρας. Το πρώτο αντικείμενο στην μπροστινή σελίδα ήταν μια διαφήμιση για ένα χαμένο Λαμπραντόρ.
Ανάμεσα στις ιστορίες και στα αποσπάσματα ποίησης, το ένα τρίτο αυτής της πίσω σελίδας καλύπτεται με καλά γεγονότα (well facts). Ένας αναλυτικός πίνακας για τις δαπάνες των σχολείων της περιοχής που όπως αναφέρει ο «ΝΗ» (πηγή) δεν είχε ποτέ πριν βγει στη δημοσιότητα.
Ο ΝΗ ήθελε τα δεδομένα του να δημοσιευτούν επειδή διαφορετικά τα γεγονότα θα έμεναν να παρουσιαστούν από ανεκπαίδευτους κληρικούς. Το κίνητρο του ήταν το εξής, «με τόση πληροφορία που περιέχουν είναι πολύτιμα• επειδή, χωρίς να γνωρίζουμε τον βαθμό στον οποίο η εκπαίδευση …επικρατεί, οι καλύτερες δυνατές γνώμες που μπορούν να διαμορφωθούν από την κατάσταση και τη μελλοντική εξέλιξη της κοινωνίας πρέπει, απαραιτήτως να είναι λανθασμένες». Με άλλα λόγια, εάν οι άνθρωποι δεν ξέρουν τι συμβαίνει, πως θα μπορέσει η κοινωνία να γίνει καλύτερη;
Δεν μπορώ να φανταστώ τώρα μια καλύτερη επεξήγηση για το τι προσπαθούμε να κάνουμε. Ότι κάποτε αποτελούσε μια ιστορία στις πίσω σελίδες, τώρα μπορεί να αποτελέσει κύρια είδηση της πρώτης σελίδας.
— Simon Rogers, the Guardian